AI & ML
Open RAG Eval’s core contribution is that UMBRELA and AutoNuggetizer are designed to score RAG quality without golden answers or golden chunks — which makes large-scale benchmarking more practical, but also means the metric family is optimizing for scalable proxy evaluation rather than proving true factual correctness.
23 min read
AI & ML
Chunking often matters as much as the embedding model itself — the 2025 NAACL Vectara study tested 25 chunking configurations across 48 embedding models and found chunking choice can shift retrieval quality by up to about 9 percentage points on the same corpus — but you must benchmark end-to-end because retrieval recall and answer accuracy can move in opposite directions.
21 min read
AI & ML
Matryoshka representation learning trains embeddings so the prefix dimensions remain useful on their own — enabling truncation without retraining — but the trade-off is that lower dimensions preserve less signal, so the article must distinguish what the paper proves about truncation from what it does not prove about every downstream corpus.
19 min read
AI & ML
TensorRT-LLM’s large-scale expert parallelism adds online workload balancing and NVLink-aware communication kernels so MoE traffic can be redistributed dynamically across GPUs — but the architecture is tightly coupled to NVIDIA’s hardware and the load-balancing logic can trade lower imbalance for extra scheduling and communication complexity.
22 min read
AI & ML
BGE-M3 is designed as a single model that unifies dense, lexical, and multi-vector/ColBERT-style retrieval across 100+ languages and long inputs up to 8192 tokens — but its benchmark story is only meaningful if you read it alongside the reranker, because the model card shows reranking and multi-retrieval are complementary rather than interchangeable.
32 min read
AI & ML
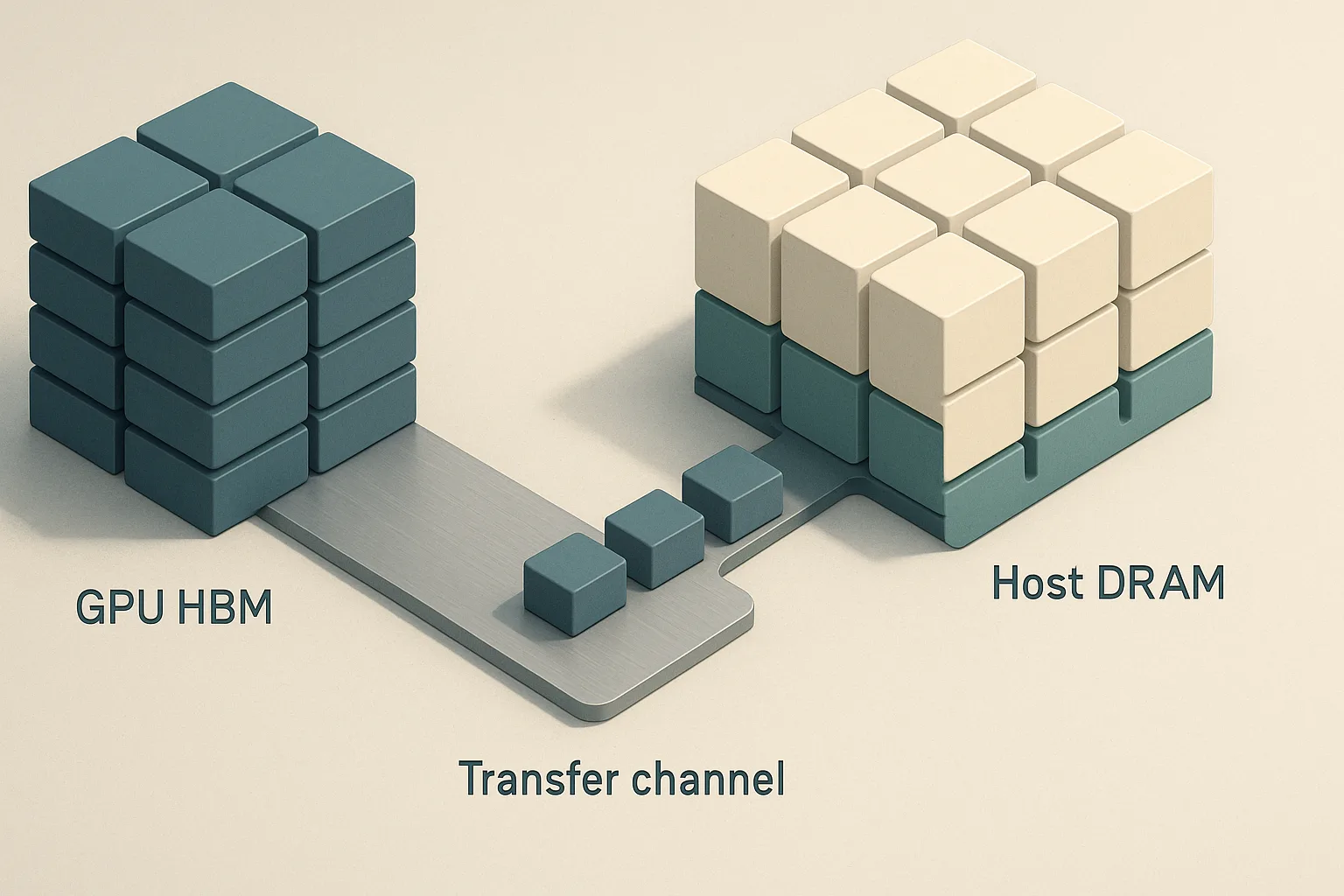
Offloading KV cache to host memory can raise effective concurrency when HBM is the bottleneck, but the article should frame it as a spend-shift decision: lower GPU-memory pressure and fewer OOMs versus higher TTFT and the hidden cost of extra system complexity, PCIe/NVLink traffic, and platform engineering time.
22 min read
AI & ML
Filtered vector search is not one algorithm but a planner choice among pre-filtering, post-filtering, and inline-filtering: high-selectivity filters favor pre-filtering, low-selectivity filters favor post-filtering, and medium-selectivity filters can use inline strategies, but stale selectivity estimates can make the planner choose badly and hurt recall/latency.
24 min read
AI & ML
pgvector is the right default when you already run PostgreSQL and need vector search joined to relational data, but the cited guidance says dedicated vector databases become worth evaluating around 50M+ vectors or when you need extremely low latency or built-in hybrid search.
21 min read
AI & ML
On a 50M-vector benchmark, pgvectorscale/Postgres delivered 11.4x higher throughput than Qdrant at 99% recall (471.57 QPS vs 41.47 QPS) while Qdrant kept lower tail latency, but the result is workload-dependent and the Tiger Data comparison notes index build speed and operational trade-offs still matter.
16 min read
AI & ML
Smaller embedding dimensions can materially reduce vector storage and index cost — for large corpora the difference between 3072-dim float32 and compressed 1024-dim representations can exceed 100GB — but the savings only matter if your recall loss stays inside the business tolerance for the workload.
18 min read
AI & ML
MoE++ adds zero-computation experts (zero, copy, constant) so tokens can discard, skip, or replace the MoE path, while gating residuals inject the previous layer’s routing signal to stabilize expert selection — but the design only pays off when FFN experts are the real bottleneck and zero-cost experts are deployed locally on every GPU to avoid communication overhead.
21 min read
AI & ML
Hybrid edge-cloud routing can cut inference cost dramatically because local queries avoid API spend, latency, and data egress, but the business case only holds when the on-device model can service the majority of traffic — otherwise the infra and platform overhead wipe out the savings.
17 min read