AI & ML
RedPajama-V2 pairs 100B+ raw documents from 84 Common Crawl dumps with 40+ precomputed quality annotations and duplicate IDs, letting teams build filtered subsets without starting from scratch — but it remains a raw corpus that still requires policy decisions about which signals to trust and how aggressively to deduplicate.
19 min read
AI & ML
FineWeb-Edu is a 1.3T-token educational subset of FineWeb whose paper reports large gains on knowledge- and reasoning-heavy evaluations, including higher MMLU and ARC scores than the base FineWeb subset — but the lift comes from a carefully filtered educational slice, not from adding more generic web text.
20 min read
AI & ML
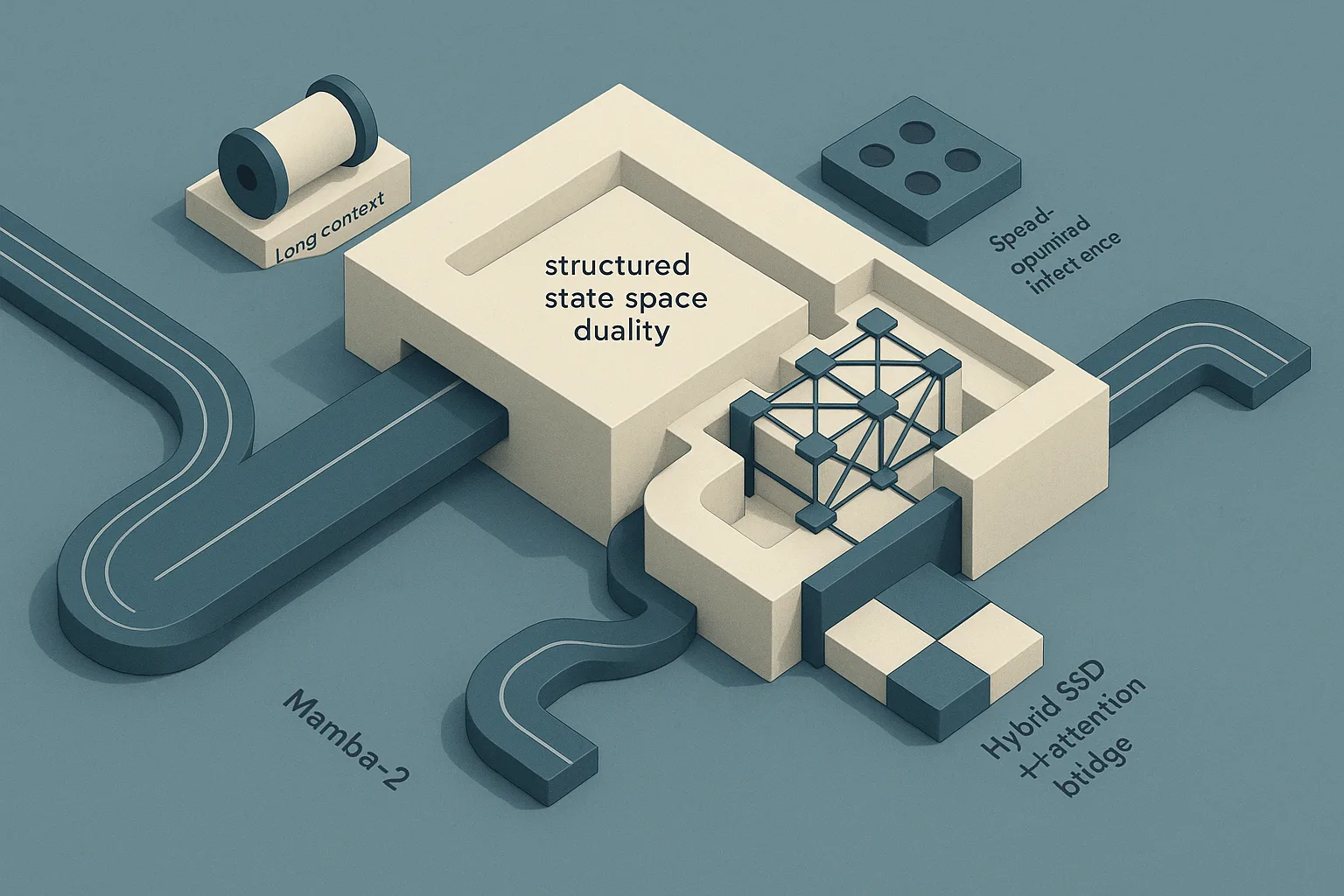
Structured State Space Duality shows Mamba-2 and masked attention are two contraction orders over the same semiseparable structure — yielding a core layer that is 2–8× faster than Mamba’s fused scan and competitive with Transformers, but the gains are most compelling for long sequences and the paper still shows better quality when a few attention layers are mixed in.
23 min read
AI & ML
PyTorch Context Parallel shards long sequences across devices so each rank only holds a context slice for attention and KV handling — this makes 1M-token training feasible in the PyTorch/Torchtitan workflow — but it is still a distributed training feature that depends on correct process-group setup, NCCL communication, and long-context-aware model partitioning.
20 min read
AI & ML
RULER demonstrates that needle-in-a-haystack is a superficial long-context test because models can score near-perfectly there and still collapse on multi-hop tracing and aggregation as sequence length grows, while LongBench v2 shows that realistic long-context multitasks still defeat most models — the best direct-answer system only reaches 50.1% and even human experts sit at 53.7% under time pressure.
18 min read
AI & ML
RULER shows that many models look near-perfect on vanilla needle-in-a-haystack yet suffer large drops as context length and task complexity rise, while LongBench v2 shows the best direct-answer model still reaches only 50.1% accuracy and o1-preview reaches 57.7% — but that gap does not automatically justify retraining, because the right choice depends on whether your workload needs deeper reasoning, not just longer windows.
21 min read
AI & ML
For 100K-token workloads, long context can be the right tool for global document understanding or implicit queries, but production economics are often brutal: the cited 2026 decision framework says 1M-token requests can run 30–60x slower and roughly 1,250x more expensive per query than RAG — with the main caveat that long context still wins when the answer depends on relationships across the whole corpus.
17 min read
AI & ML
RULER shows that near-perfect needle-in-a-haystack scores can mask steep degradation on harder long-context tasks — the paper evaluates 17 models across 13 tasks and finds that almost all drop sharply as context length increases, with only half maintaining satisfactory performance at 32K — but synthetic benchmark success still does not guarantee real-world long-context reliability.
17 min read
AI & ML
Google’s deduplicate-text-datasets provides exact substring deduplication in Rust plus near-duplicate clustering for large corpora, while Ambrosia is a lightweight package aimed at ergonomics — but the deciding constraint is scale and rigor, because Google’s repo is built for research-grade dataset deduplication with very large-memory jobs, whereas simpler tools trade accuracy and reproducibility for convenience.
19 min read
AI & ML
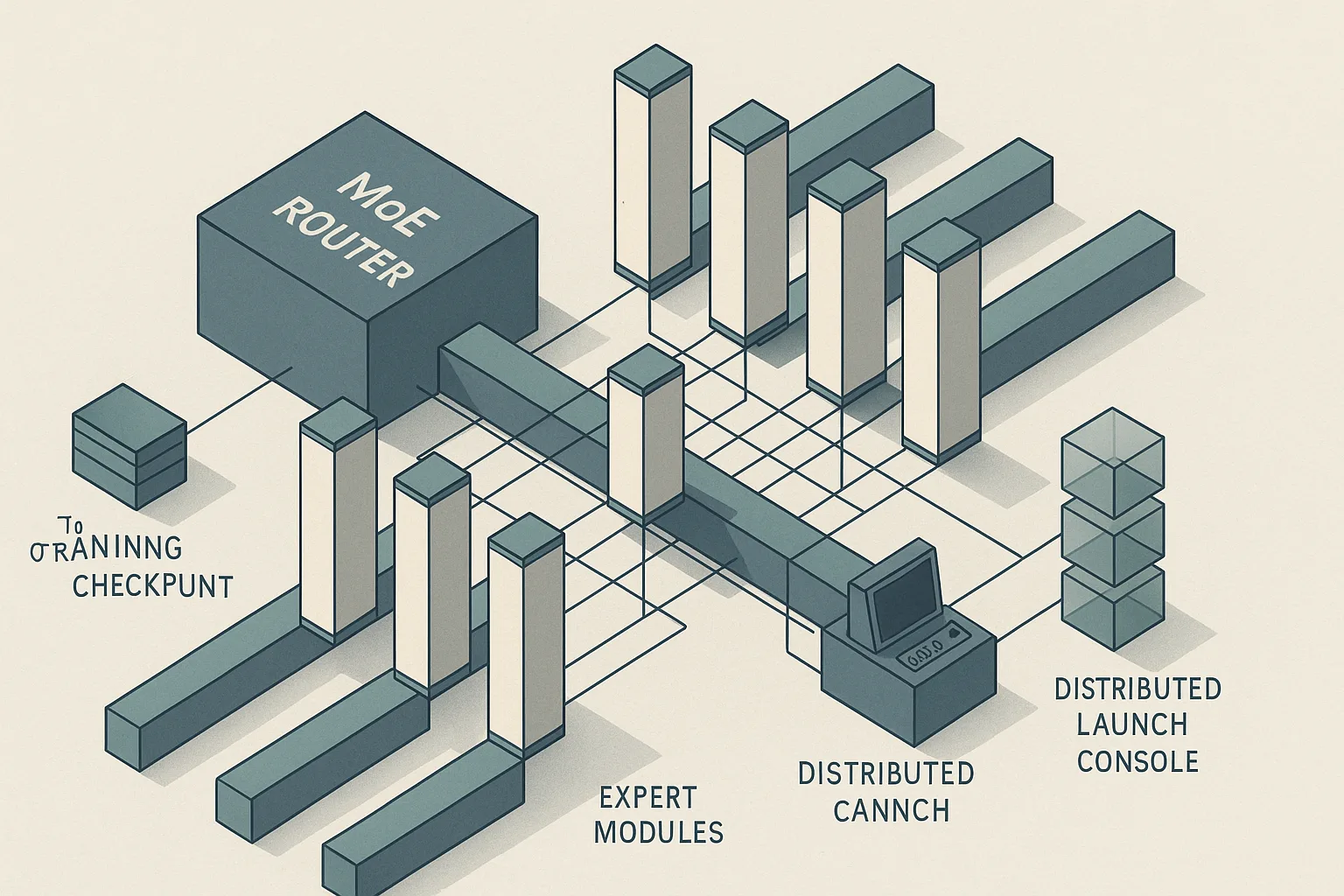
Megatron-Core’s MoE stack is production-ready for large-scale MoE training and exposes routing, expert-parallel, and capacity controls that matter when fine-tuning Mixtral — but the official docs emphasize that the exact behavior depends on parallelism layout, router configuration, and capacity settings rather than a one-size-fits-all recipe.
15 min read
AI & ML
DeepSeek-V3 is benchmark-relevant not just because it is large, but because it combines auxiliary-loss-free load balancing, multi-token prediction, and FP8 training at scale — and MLCommons is now using it as a pretraining benchmark with a 671B/37B MoE reference setup, making it a meaningful test of modern sparse-training infrastructure rather than just another model card.
22 min read