AI & ML
LongRoPE exploits two non-uniformities in RoPE interpolation — across RoPE dimensions and token positions — and uses an evolutionary search to find per-dimension, per-position rescaling factors, which enables an 8× non-finetuning extension and then a progressive 256k→2048k extension path — but it still needs short-context readjustment to recover original-window performance.
20 min read
AI & ML
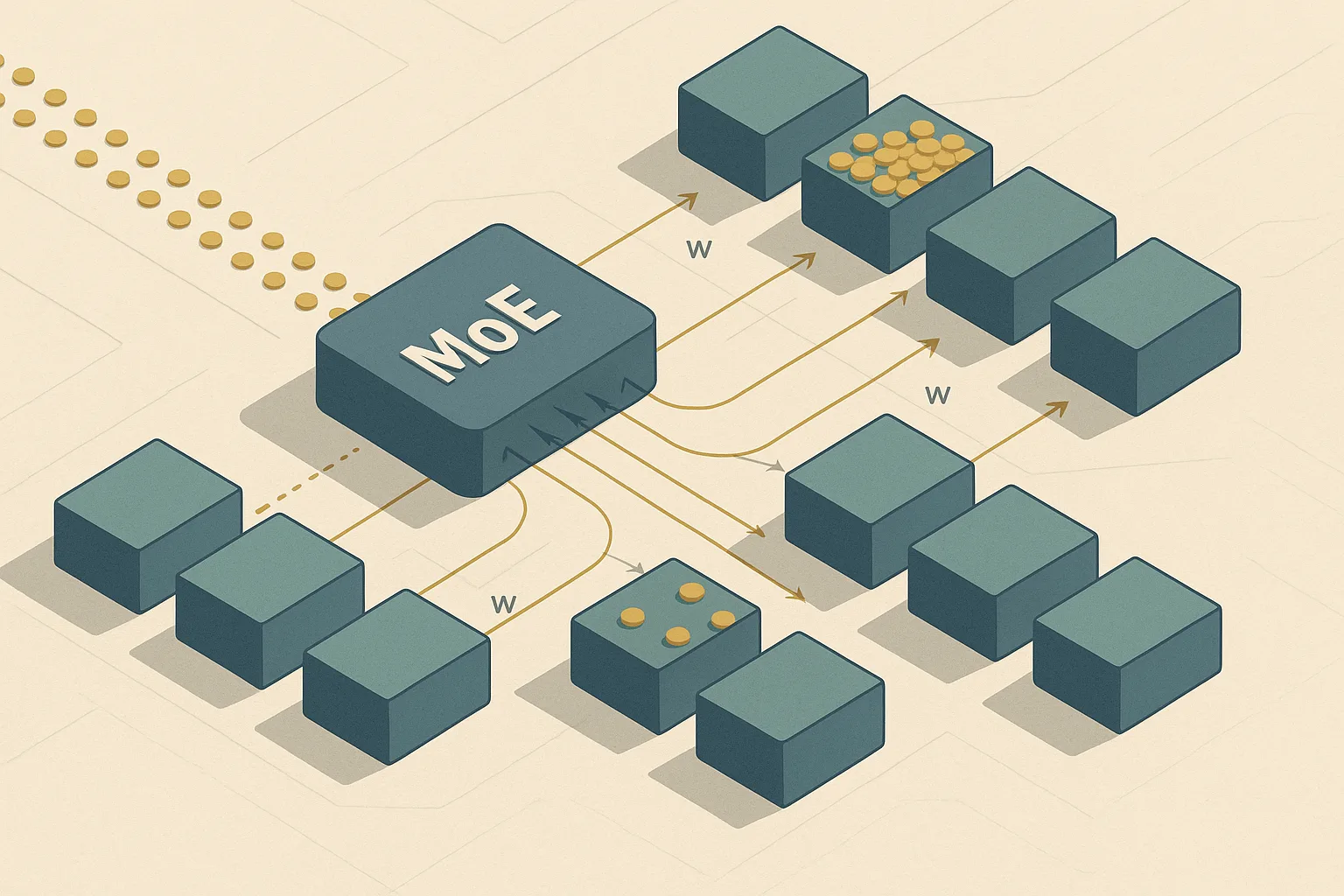
DeepSeek-V3 replaces the usual router auxiliary loss with a dynamically adjusted per-expert bias term for load balancing — preserving the load-balancing goal while avoiding the performance degradation the paper attributes to heavy auxiliary losses, but the benefit is tied to sequence-wise balance and node-limited routing rather than eliminating imbalance entirely.
22 min read
AI & ML
LongRoPE pushes the ceiling to 2M tokens with a more complex search-and-progressive-extension pipeline, YaRN is validated in vLLM/Qwen deployment paths for practical length extrapolation, and dynamic NTK scaling is simpler to wire up — but the real trade-off is not raw maximum length alone; it is how much short-context regression, finetuning, and framework-specific friction you are willing to accept.
23 min read
AI & ML
At small scale, SLERP is clean for two-model interpolation and TIES/DARE handle multi-model interference better, while mergekit is the orchestration layer that exposes them all — but the best choice changes with model count, compatibility, and whether you want a simple blend or sign-aware pruning.
17 min read
AI & ML
FlashAttention installation is constrained by CUDA, PyTorch, Ninja, and GPU architecture support — and benchmark results are only trustworthy when head-dim limits, dtype support, and backend compatibility are matched to the target GPU, otherwise users hit build failures or misleading speed numbers.
22 min read
AI & ML
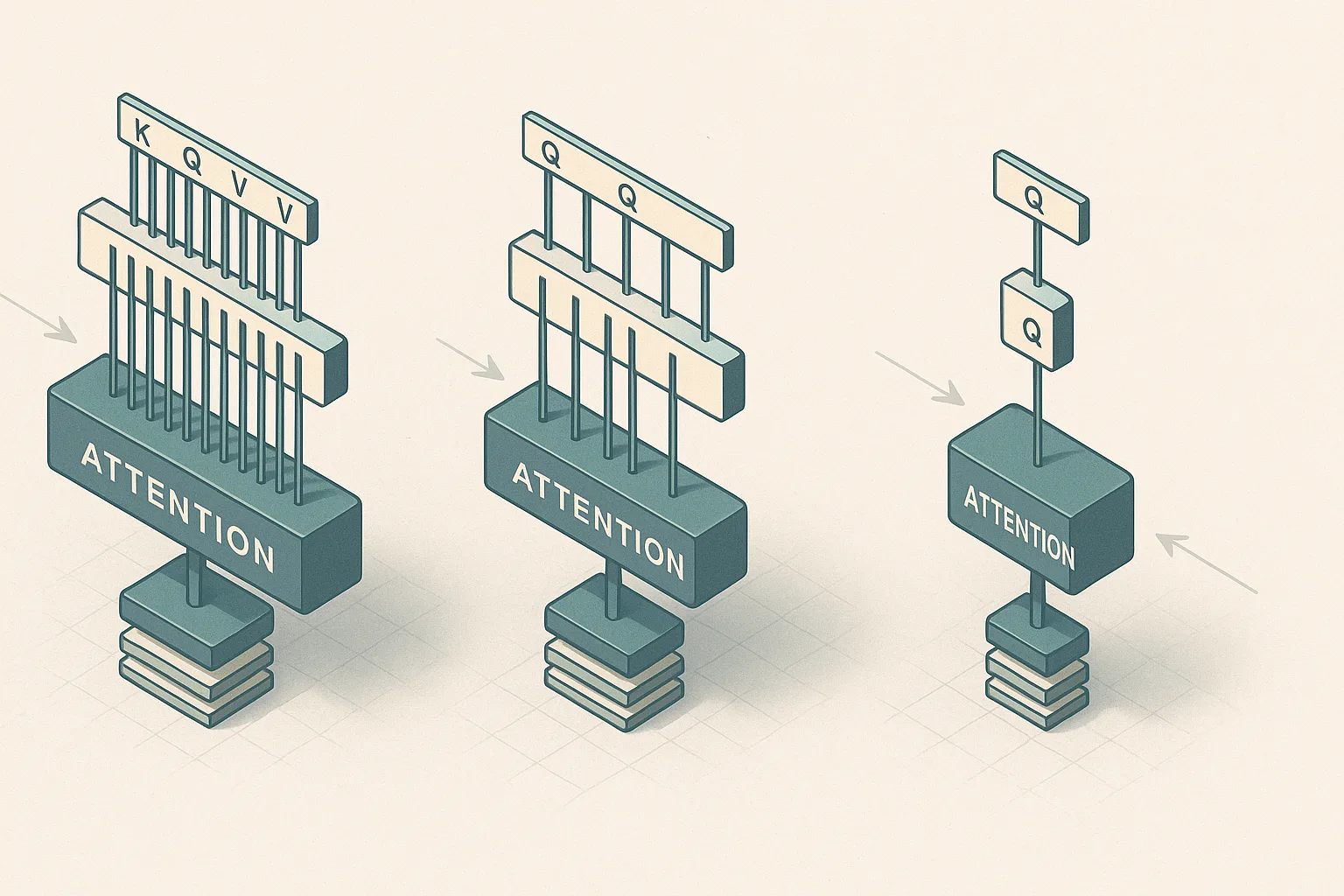
GQA reduces KV-cache size by sharing K/V across query groups, which cuts inference memory bandwidth versus MHA while preserving more quality than MQA — but the right group size depends on the latency budget, context length, and whether the model must stay close to full multi-head capacity.
25 min read
AI & ML
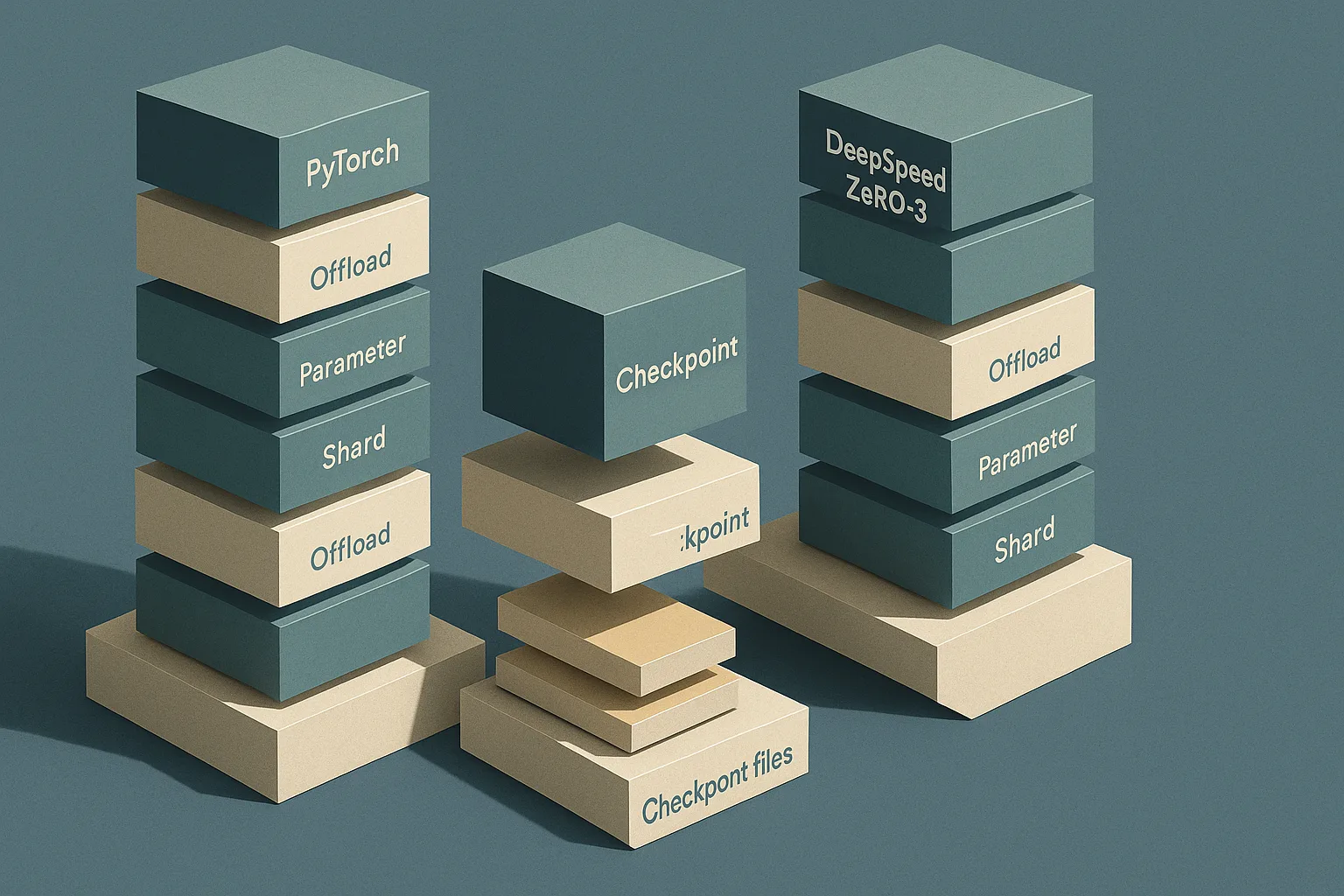
Accelerate maps FSDP FULL_SHARD to DeepSpeed ZeRO stage 3, but the two stacks diverge on offload and checkpointing: FSDP is all-or-nothing for offload, while DeepSpeed can split parameter and optimizer offload and even target NVMe — but FSDP can checkpoint sharded state directly, whereas ZeRO-3 often needs a consolidation or post-conversion step, which changes the operational cost of saving 70B fine-tunes.
20 min read
AI & ML
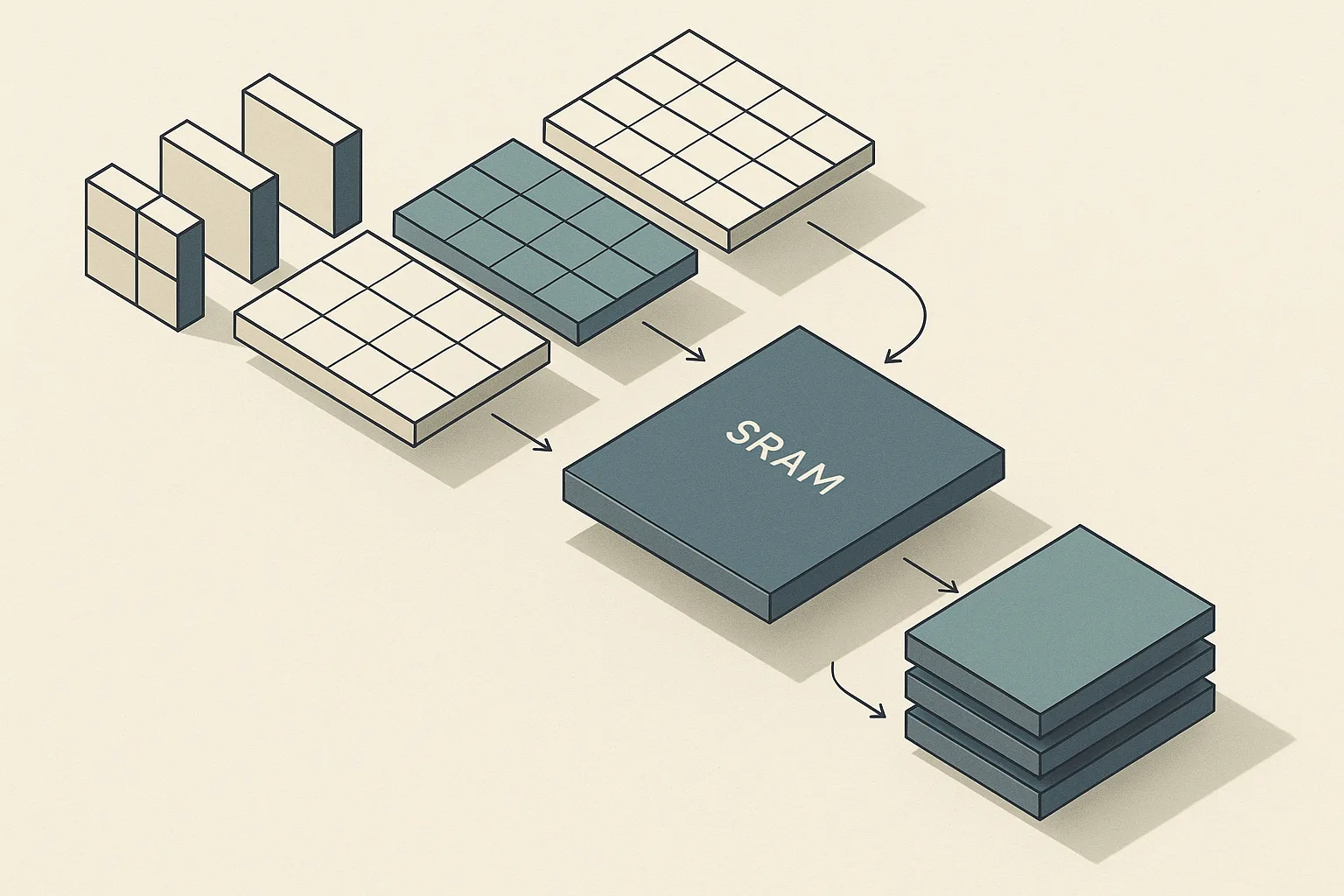
FlashAttention keeps attention exact while reducing HBM traffic by tiling Q/K/V into SRAM and recomputing rather than materializing the N×N attention matrix — yielding linear-memory behavior and major wall-clock gains, but only when the GPU memory hierarchy and tile sizes are exploited correctly.
18 min read
AI & ML
vLLM’s Qwen deployment docs explicitly recommend RoPE scaling for context lengths beyond the pretrained 32,768-token limit and validate YaRN for length extrapolation — but the exact scaling knobs must be matched to the model’s original max position embeddings and sampling/runtime settings, or the model can silently degrade even if it accepts longer prompts.
18 min read
AI & ML
QLoRA makes 8B-class models practical on 24GB cards by combining 4-bit NF4 quantization with LoRA adapters, but the memory win comes with slower training than plain LoRA and tighter sensitivity to sequence length, batch size, and target module choice.
22 min read
AI & ML
S-LoRA is optimized for high-scale multi-adapter serving through unified paging and heterogeneous batching, LoRAX is designed for thousands of adapters with dynamic loading and production features, and vLLM PEFT is the lighter-weight option when you want vLLM’s serving stack with adapter support but not the most aggressive multi-adapter specialization.
20 min read
AI & ML
Buying curated preference data reduces internal labeling and curation labor, but the trade-off is vendor dependency and less control over sampling and rubric design — in practice, teams should expect the cheapest path to be purchase for experimentation and the best path to be build when they need domain-specific preference signals, auditability, or iterative rubric changes.
24 min read