AI & ML
While ReAct reduces single-step latency by 48%, empirical benchmarks show AgentX achieves a 62.1% reduction in total token consumption for long-horizon tasks by enforcing stage-wise context summarization, albeit at the expense of higher orchestration complexity.
10 min read
AI & ML
By utilizing HiPPO-initialized SSM side-car modules, engineers can theoretically achieve O(1) state inference latency and persistent memory, albeit at the cost of significantly increased integration complexity compared to traditional Transformer-only architectures.
15 min read
AI & ML
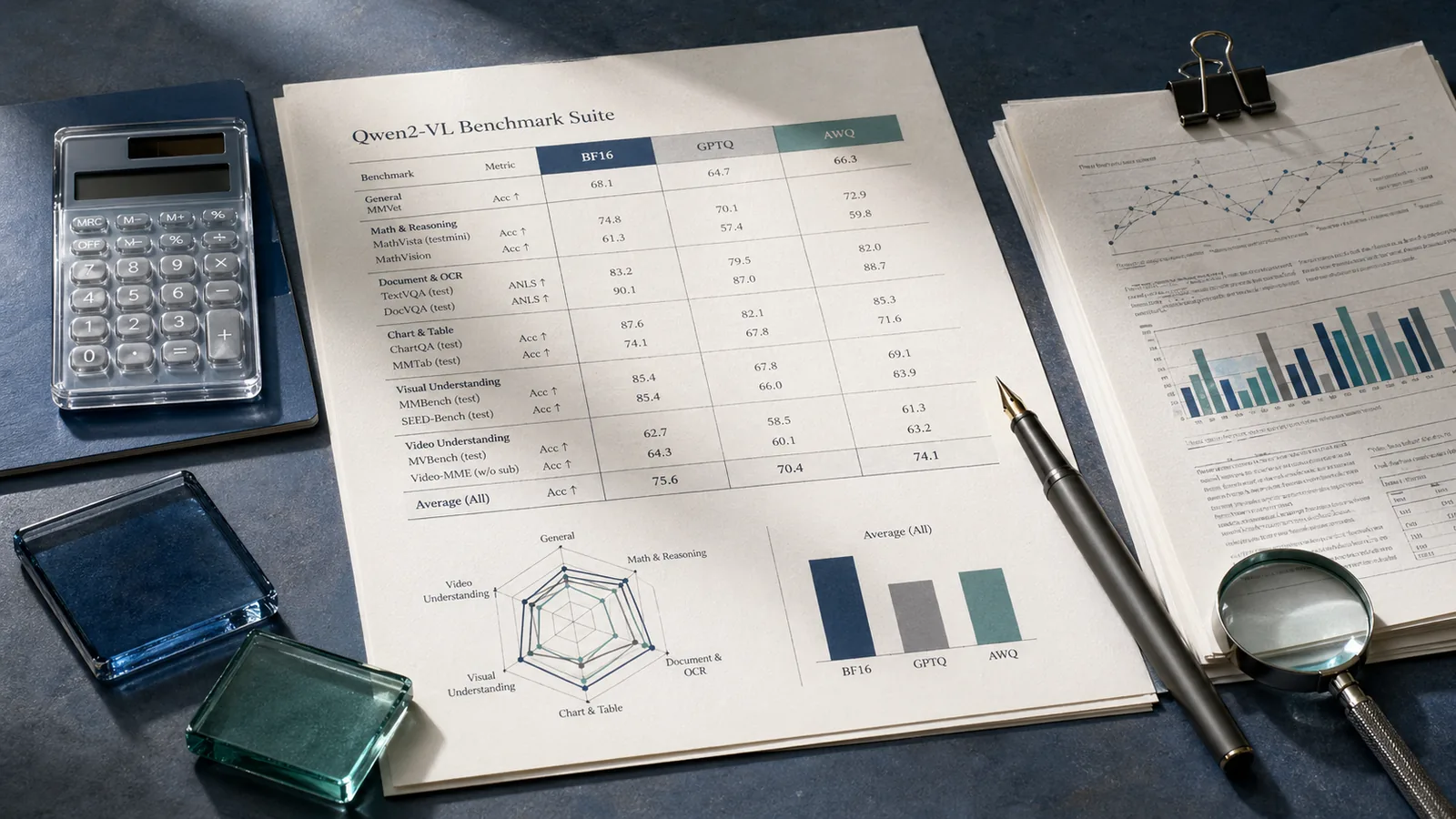
On Qwen2-VL-2B-Instruct, GPTQ-Int4 preserves most multimodal quality but still shows measurable drops versus BF16 on harder vision-language tasks — for example, MMMU falls from 41.88 to 39.22 and MathVista from 44.40 to 41.69 — while DocVQA stays comparatively stable, implying task sensitivity matters more than the bit-width label alone.
18 min read
AI & ML
By utilizing Chain-of-Attack-Thought reasoning within a hierarchical attack planner, security engineers can increase multi-turn jailbreak discovery rates by over 40% compared to static prompt sets, albeit at the cost of high-latency inference during the adversary planning phase.
16 min read
AI & ML
By utilizing a transformer-based triplane-NeRF architecture, engineers can achieve sub-0.5s feed-forward 3D reconstruction, albeit at the cost of high 6GB VRAM memory overhead per single-image input.
16 min read
AI & ML
GGUF with llama.cpp is the lowest-friction path to portable local inference across CPU, Apple Silicon, and heterogeneous devices — but the trade-off is that you accept manual conversion and tuning in exchange for avoiding GPU cloud costs and vendor lock-in.
18 min read
AI & ML
By transitioning from capital-heavy on-premise clusters to GPU-as-a-Service (GPUaaS) models, enterprises can reduce infrastructure TCO by 30-40%, provided they implement liquid cooling and high-density rack power management to maintain uptime for sustained, high-intensity inference workloads.
16 min read
AI & ML
By implementing AWQ (Activation-Aware Weight Quantization) alongside speculative decoding, engineering teams can achieve a 3-4x throughput improvement while keeping accuracy degradation under 1%, though this necessitates careful management of the KV-cache memory overhead during parallel request batching.
15 min read
AI & ML
Knowledge-graph agentic RAG works by using entity links and graph traversal to expand the evidence frontier beyond nearest-neighbor chunk retrieval — this improves multi-hop recall when relationships matter — but it depends on strong entity resolution and graph quality, so noisy extraction can amplify wrong paths rather than fix them.
26 min read
AI & ML
Jointly applying Knowledge Distillation during Quantization-Aware Training (QAT) reduces the 'accuracy floor' typical of ultra-low bit-width models by transferring the inductive biases of the teacher model directly into the quantized weight space of the student, mitigating the signal loss inherent in post-training quantization.
14 min read
AI & ML
By implementing a three-layer RAG measurement framework—measuring retrieval precision@k, generation faithfulness, and business resolution rates—enterprises can detect silent system degradation before it impacts user experience, typically surfacing issues 20% earlier than anecdotal monitoring.
16 min read
AI & ML
Optimizing pass@N performance is no longer a matter of scaling sample counts; by implementing dynamic early-exit policies and gradient-based token refinement, production teams can minimize tail latency spikes without sacrificing logical consistency in complex reasoning tasks.
15 min read