AI & ML
By deploying DINOv2 backbones for spatial-adaptive feature extraction in 3D surrogate models, teams can reduce inference latency by 7.6x in GNSS-denied environments while maintaining sub-10m localization error.
16 min read
AI & ML
Integrating Small Modular Reactors (SMRs) directly behind the meter offers hyperscalers a solution to 5-12 year grid interconnection delays, provided they can manage the high initial CapEx and strict regulatory compliance requirements.
16 min read
AI & ML
By implementing a router-worker audit framework, engineering teams can quantify contamination-induced score inflation by comparing baseline performance against perturbed, semantic-shifted benchmark variants, though it requires a 2x-3x increase in inference volume for robust statistical confidence.
14 min read
AI & ML
Selecting a red teaming framework is a trade-off between Garak's 'wide-net' known-exploit automation and PyRIT's 'deep-context' multi-turn capability, with the latter requiring 4x the security engineering headcount to achieve comparable ROI in complex production environments.
19 min read
AI & ML
By utilizing ST-GATs, financial engineers can capture non-linear, time-varying dependencies in interbank lending networks with a 15% improvement in contagion prediction precision over standard VAR models, though training requires significant GPU memory for multi-head attention over large-scale adjacency matrices.
15 min read
AI & ML
By implementing a 50/50 real-to-synthetic data ratio combined with uncertainty-based active learning sampling, engineers can maintain model performance across long-tail distribution edge cases, provided the synthetic data undergoes rigorous geometric and semantic validation to avoid feature drift.
17 min read
AI & ML
Agentic retrieval can improve enterprise answer quality for multi-source and multi-hop requests, but it also adds orchestration, observability, and governance overhead — the business case hinges on whether the error reduction and self-service gains outweigh slower responses and higher operational complexity.
19 min read
AI & ML
By implementing the OFT recipe—combining parallel decoding and L1 regression—engineers can achieve a 26x increase in action generation throughput, though it requires specific attention to proprioceptive state normalization to maintain closed-loop control stability.
16 min read
AI & ML
For regulated teams, the right agent-security decision is usually not 'tooling or not' but where to place the enforcement boundary — buying policy gateways and audit tooling can reduce time-to-control, but building inside the MCP stack preserves tighter ownership over scopes, logs, and approval paths — at the cost of higher engineering and maintenance burden.
21 min read
AI & ML
By transitioning workloads from TPU v5e to Trillium (v6), engineers can achieve a 4.7x increase in peak compute per chip and 2x HBM bandwidth, but must refactor embedding layers to fully utilize the specialized third-generation SparseCore for recommendation-heavy models.
13 min read
AI & ML
By deploying AutoResearch-RL to separate the frozen environment from the mutable training script, teams can recover up to 2.4x more experiment throughput per GPU-hour via predictive early-stopping of unpromising training runs.
19 min read
AI & ML
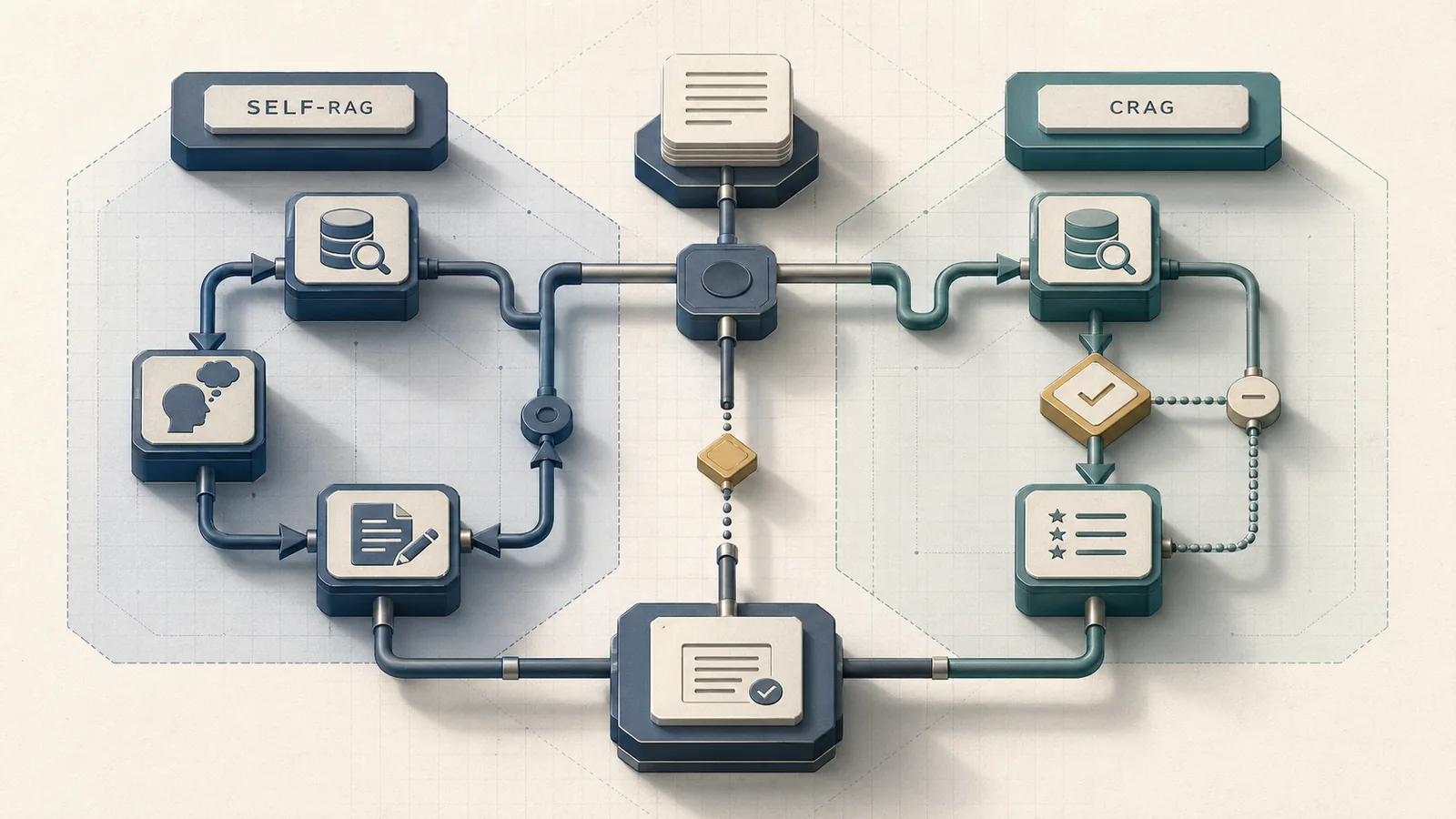
CRAG is better when retrieval ambiguity is the problem because it adds a lightweight evaluator plus web-search fallback, while Self-RAG is better when you want the model itself to self-reflect through retrieval and support checks — but Self-RAG’s richer control logic usually costs more LLM calls, so the best choice depends on latency budget and how much correction you need.
20 min read