What Qwen3-Coder-Next's tool chat template actually encodes
The tool chat template in Qwen3-Coder-Next is not decorative markup — it is the primary mechanism that transforms a structured message list into a token sequence the model was trained to parse and act on. When tool calling fails silently after fine-tuning or under a new serving stack, the template is almost always the proximate cause, not the weights.
The Qwen2.5-1.5B-Instruct model card demonstrates the canonical path explicitly: a Python messages list is converted to a generation-ready prompt via tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) before model.generate(...) is called. That call is not a convenience wrapper — it applies a Jinja template embedded in tokenizer_config.json that inserts role delimiters, special tokens, and structured tool-call blocks in positions the model was trained to expect. The vLLM tool calling docs confirm that for Qwen2.5, the tokenizer_config.json already carries Hermes-style tool-use support, which is why parser choice is a deployment requirement rather than a post-hoc tuning knob.
Bottom Line: Qwen3-Coder-Next's tool chat template encodes tool calling and tool responses as first-class structured chat turns with role-specific delimiters and parser-recognizable call blocks; any deviation from the expected serialization — whether during training data construction or inference-time serving — will silently corrupt tool-use behavior before it ever surfaces as an obvious error.
Why agentic SFT depends on strict message boundaries
Agentic SFT teaches the model two distinct behaviors: when to emit a structured function call, and when to consume a tool result and produce a natural-language answer. These two behaviors must be associated with different token regions in the training transcript. If assistant tool-call turns and tool-response turns are merged or mislabeled, the supervision signal collapses: the model sees prose where it should see structured output, or structured output where it should see execution state.
The stakes are concrete. A 2025 arXiv study on agentic data synthesis reports that "before agentic SFT, the specialized model fails almost completely on BFCL," and specifically documents that Goedel-Prover-V2-32B-SFT achieves near-zero function-calling accuracy on the Berkeley Function-Calling Leaderboard when trained without proper tool-use transcripts. The BFCL benchmark measures exactly this behavioral gap — whether the model can correctly identify when to invoke a function and whether it formats the invocation parsably.
The mechanism behind the failure is structural: merging an assistant tool-call block with a user or tool turn converts the transcript into plain chat text. The model no longer sees the supervised target for "emit a call here" because the boundary that separated that action from surrounding context no longer exists in the training data.
Pro Tip: When constructing training transcripts for agentic SFT, treat the
assistantrole and thetoolrole as distinct atomic units. Never concatenate tool call output into an assistant message, and never embed tool responses in user turns. The role label is part of the training signal, not just organizational metadata.
Where tokenization starts to matter
Template drift — the condition where the template used during training differs from the template applied at inference — produces outputs that are structurally valid to a human reader but unparseable by the serving stack. This failure is silent in the sense that the model generates text without raising an exception, but the tool parser extracts nothing.
The vLLM documentation for Qwen3.5/Qwen3.6 makes the coupling explicit: for Qwen2.5, the tokenizer_config.json already encodes Hermes-style tool use, and the serving command must match. For Qwen3.5/Qwen3.6 variants, the vLLM Qwen3.5/Qwen3.6 usage guide requires --enable-auto-tool-choice --tool-call-parser qwen3_coder on the serve command. Omitting those flags means the runtime does not attempt to extract tool calls from generation output, regardless of what the model emits.
Tokenizer internals contribute a subtler failure mode. Special tokens mark the boundaries of tool-call and tool-response regions. If a custom tokenizer vocabulary modifies these tokens — even by changing whitespace padding or byte-level encoding — the model will decode boundary positions incorrectly. The result is either phantom boundaries (the parser extracts garbage) or missing boundaries (the parser sees no call at all).
Watch Out: When fine-tuning on a modified tokenizer, verify that tool-boundary special tokens survive the vocabulary change with identical IDs and encodings. A single-token ID shift in
<tool_call>or</tool_call>will cause the parser to extract zero calls at inference time, with no error message to indicate the cause.
How the Qwen chat flow serializes system, user, assistant, and tool turns
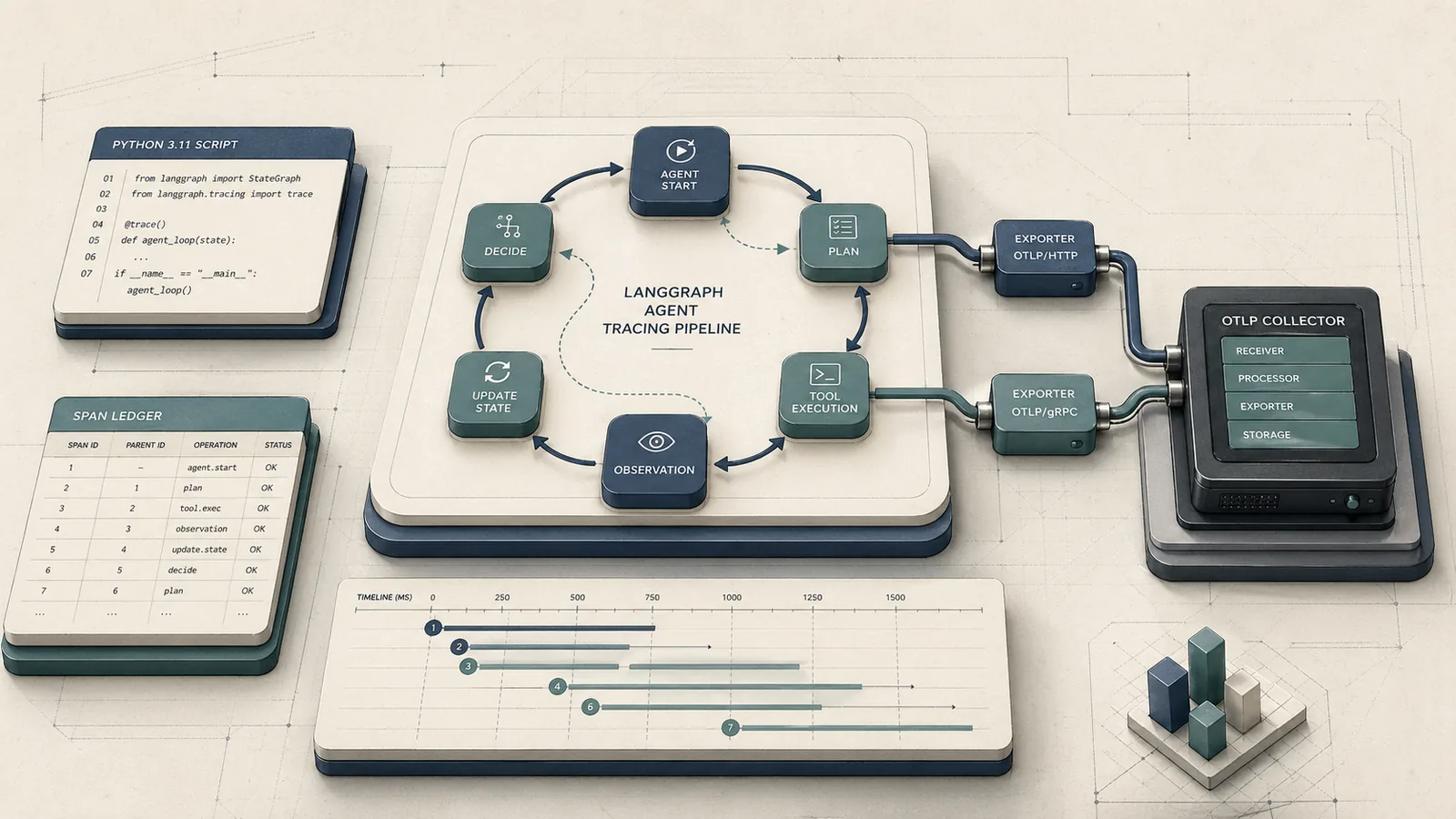
The Qwen chat pipeline has two logically separate stages: serialization (converting a structured message list to a flat token sequence) and parsing (recovering structured tool calls from the generated token sequence). These stages share a contract — the Jinja template in tokenizer_config.json — and failures occur when that contract is applied inconsistently between them.
The following ArchitectureDiagram shows how prompt-list serialization, generation, parsing, and tool-result reinsertion fit together in the Qwen flow.
flowchart LR
A["messages list\n[{role, content}, ...]"] --> B["apply_chat_template()\n(Jinja in tokenizer_config.json)"]
B --> C["Flat token sequence\n<|im_start|>system..."]
C --> D["model.generate()"]
D --> E["Raw generation output\n(may contain tool-call blocks)"]
E --> F{"Tool parser\n(hermes / qwen3_coder)"}
F --> G["Structured ToolCall object\n(function name + args)"]
F --> H["Natural language answer\n(no call detected)"]
G --> I["Execute tool\nReturn result"]
I --> J["Re-serialize: insert tool\nresult as role=tool turn"]
J --> B
The loop terminates when model.generate() produces output that the parser routes to H rather than G — meaning the model has consumed all tool results and is generating a final answer. Every iteration passes through apply_chat_template again, which is why the template must remain byte-identical across iterations.
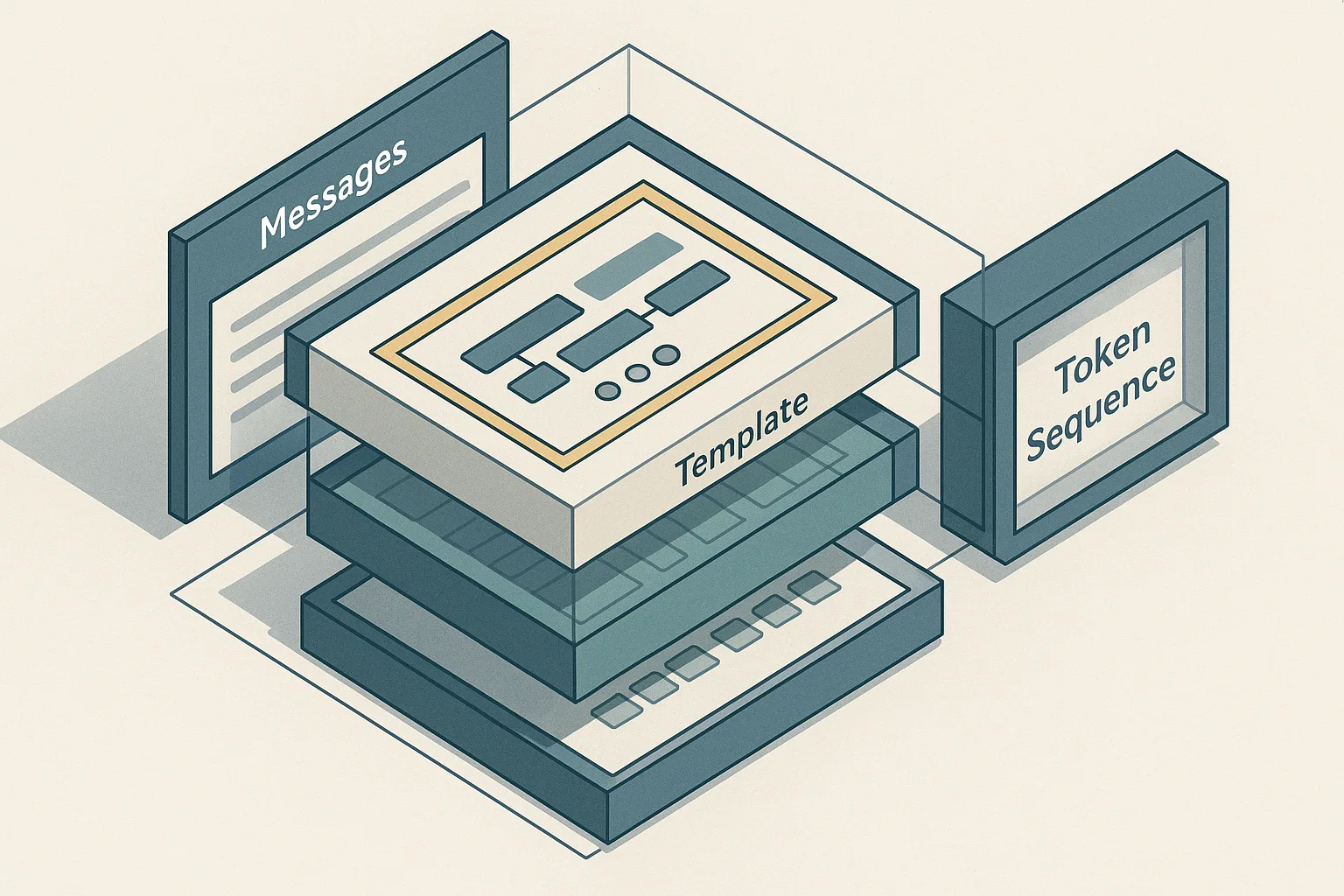
From message list to templated prompt
The message list is a Python list of dicts, each with at minimum role and content keys. The Qwen family uses ChatML-style roles: system, user, assistant, and tool. The Jinja template in tokenizer_config.json iterates this list and wraps each entry with role-specific start and end tokens — <|im_start|>role\ncontent<|im_end|> in the canonical Qwen format — then appends an <|im_start|>assistant\n prefix to prime generation.
The Qwen2.5-1.5B-Instruct model card shows this path directly: tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True). The add_generation_prompt=True argument appends the open <|im_start|>assistant\n token without a closing <|im_end|>, which is the generation anchor — the point from which the model continues. If add_generation_prompt is omitted or set to False, the model receives a prompt that looks like a completed exchange and may continue the prior turn rather than starting a fresh assistant response.
sequenceDiagram
participant ML as messages list
participant T as apply_chat_template
participant TS as Token sequence
ML->>T: [{role:"system",content:"..."}, {role:"user",content:"..."}, ...]
T->>TS: <|im_start|>system\n...<|im_end|>\n
T->>TS: <|im_start|>user\n...<|im_end|>\n
T->>TS: <|im_start|>assistant\n ← generation anchor
Note over TS: model.generate() resumes from here
How assistant tool calls are represented
When the model decides to invoke a tool, it generates a structured block inside the assistant turn rather than natural language. The Qwen-Agent README states that "the current default tool calling template natively supports Parallel Function Calls," and specifies that the default tool-call template is nous, recommended for Qwen3. The nous format wraps each call in explicit XML-like tags with a JSON payload containing the function name and arguments.
A well-formed assistant tool-call turn looks structurally like this — the model emits the call block, then closes the assistant turn with <|im_end|>:
<|im_start|>assistant
<tool_call>
{"name": "search_code", "arguments": {"query": "tokenizer special tokens", "repo": "Qwen2.5"}}
</tool_call>
<|im_end|>
For parallel calls, multiple <tool_call> blocks appear sequentially within the same assistant turn, each with its own call ID so the tool orchestrator can route responses back to the correct invocation. The parser must preserve call identity through the round trip — collapsing parallel calls into a single block or stripping call IDs is a data-construction error with direct consequences for training supervision.
Pro Tip: During SFT data construction, generate and validate each tool-call block against the target parser before writing it to the dataset. An assistant turn with malformed JSON inside a
<tool_call>block will not raise an error during tokenization — it will silently produce a training example where the model learns to generate unparseable calls.
How the tool result is reinserted before the final answer
After the tool executes, its output must re-enter the conversation as a dedicated tool role turn — not appended to the preceding assistant message, and not inserted as a user turn. The Qwen-Agent framework enforces this structure in its agent loop: each tool result maps to a role: tool message that carries the function name, call ID, and result content. This message is then appended to the messages list before the next call to apply_chat_template.
The model was trained on transcripts where tool results appear in this exact position and role. If the tool result is injected as a user message, the model treats it as human input and loses the distinction between "what the environment returned" and "what the user said." If it is appended to the assistant message that issued the call, the model sees a self-contained exchange and may skip the final synthesis step entirely.
Watch Out: Role-order corruption in multi-turn tool transcripts is one of the most common sources of degraded agentic SFT behavior. A transcript that reads
system → user → assistant[call] → assistant[result + answer]teaches the model nothing about the tool-consumption phase; all tool-use supervision is lost in the merged assistant turn.
Why the template shape matters for training data quality
Template shape is not a preprocessing aesthetic — it is the encoding of the action boundary that separates tool invocation from tool consumption. The DLLM-Searcher paper (arXiv 2602.07035) demonstrates this directly: "Agentic SFT effectively rectifies these behavioral flaws, enabling SDAR to strictly follow the requisite tool_call formats." The qualifier "strictly follow" is doing real work here. The model does not generalize to the correct format from approximate examples; it requires exact structural supervision.
The same source notes that the authors "pre-fill special boundary tokens and apply an additional confidence bias to encourage the model to decode the tool_call region with priority" — a training intervention that only becomes necessary when the boundary tokens are not reliably present in the data. In other words, when the template shape is correct and consistent across the dataset, boundary pre-filling is unnecessary; when the template is noisy, you need active countermeasures.
Production Note: When constructing an agentic SFT dataset at scale, validate transcript structure programmatically before any training run. A dataset with 5% malformed tool turns can degrade function-calling accuracy by enough to produce the near-zero BFCL scores documented in the literature. The cost of a validation pass is trivial relative to the cost of a failed training run. Specifically, check that every assistant turn containing a
<tool_call>block is followed by arole: toolturn, that everyrole: toolturn has a matching call ID, and that no tool result appears in auserorassistantturn.
Common malformed transcript patterns
Four structural failures account for most agentic SFT degradation in practice:
Merged assistant/tool turns. The tool result is appended to the assistant message that issued the call, producing a single assistant turn that both emits a call and reports its outcome. The model learns no distinction between generating a call and consuming a result.
Missing tool-response turns. The transcript jumps from the assistant tool-call block directly to the next user message or the final answer, with no intervening role: tool entry. The model learns that calling a tool is sufficient on its own — it never trains the synthesis step.
Out-of-order tool insertion. Tool results are inserted before the assistant turn that triggered them, or after the final answer. Either ordering produces a nonsensical supervision signal for the tool-consumption phase.
Unlabeled parallel call responses. For transcripts with multiple simultaneous tool calls, tool results are not matched to call IDs. The model cannot learn which result corresponds to which function, making parallel-call synthesis undefined.
The Awakening the Sleeping Agent paper confirms the consequence: near-zero BFCL accuracy in models trained without correct tool-use structure. The failure is not gradual degradation — it is near-total loss of function-calling capability.
Watch Out: Tokenizer internals amplify every structural error. When role-boundary tokens appear in unexpected positions, the tokenizer encodes them as normal token sequences rather than structural delimiters. The model then learns to treat
<|im_start|>toolas prose rather than a role boundary, which breaks not just the training example in question but every example that follows it in the same packed training batch.
What goes wrong when special tokens do not match the template
Special tokens in the Qwen family perform structural work that regular tokens cannot substitute. The <|im_start|> and <|im_end|> tokens delimit role boundaries; the <tool_call> and </tool_call> tags (in the nous format) delimit function invocation regions. The model was trained to associate these exact token IDs with specific behavioral transitions.
When a serving stack uses a parser that expects different delimiters than the template emits, extraction fails silently. The vLLM Qwen3.5/Qwen3.6 usage guide documents this concretely: Qwen2.5 uses Hermes-style tool use already embedded in tokenizer_config.json, while Qwen3.5/Qwen3.6 requires --tool-call-parser qwen3_coder. Using the hermes parser on a Qwen3-Coder-Next model means the parser is scanning for Hermes-format delimiters in output that uses nous-format delimiters — no calls will be extracted.
Pro Tip: Maintain a three-way synchronization checklist before any deployment: (1) the Jinja template in
tokenizer_config.json, (2) the parser flag passed to vLLM or SGLang, and (3) the tool-call block format used in your SFT training data. All three must agree on delimiter format, JSON schema, and call-ID field names. A mismatch at any point in the chain will produce zero extracted calls at inference time.
How Qwen3-Coder-Next differs from earlier Qwen chat templates
The comparison below isolates the differences in template structure, tool serialization, and agentic SFT behavior that matter when moving from Qwen2.5 to Qwen3-Coder-Next.
| Feature | Qwen2.5 family | Qwen3-Coder-Next |
|---|---|---|
| Base template format | ChatML / Hermes-style in tokenizer_config.json |
ChatML lineage, nous-style tool blocks |
| Tool-call serialization | Hermes-format (supported via hermes vLLM parser) |
nous-format (<tool_call> JSON blocks) |
| Parallel function calls | Limited native support | Native support per Qwen-Agent README |
| Recommended vLLM parser | hermes |
qwen3_coder |
| Qwen-Agent default template | Not specified as nous |
nous (explicitly recommended) |
| SFT behavior pre-agentic training | Function-calling accuracy variable | Requires agentic SFT for non-zero BFCL |
apply_chat_template API |
tokenizer.apply_chat_template(...) |
Same API, different Jinja template body |
The high-level role vocabulary (system, user, assistant, tool) is stable across the transition. The structural change is in how tool invocation blocks are delimited within assistant turns and which parser is required to recover them at serving time.
What stayed compatible across Qwen2.5 and Qwen3
The ChatML-style role structure is preserved across both families. The <|im_start|>role\ncontent<|im_end|> envelope applies to both Qwen2.5 and Qwen3 models, which means that non-tool-use conversations and the base apply_chat_template API remain compatible. The Transformers AutoTokenizer + apply_chat_template path works identically at the Python API level — the difference is in what the Jinja template body produces when it encounters a tool-call message.
This compatibility is load-bearing for practitioners migrating datasets: transcripts that contain only system, user, and assistant turns with no tool calls will serialize identically. Problems arise exclusively in the tool-call and tool-response regions.
The Qwen-Agent README notes that the
noustemplate is "recommended for qwen3," which implies the family-specific Jinja template body diverges at the tool-serialization branch, not at the role-envelope level. Transformers-based fine-tuning pipelines that callapply_chat_templatewith the correct tokenizer will automatically use the right template body — but only if the tokenizer loaded is the Qwen3-Coder-Next tokenizer, not a Qwen2.5 tokenizer applied to Qwen3 data.
What changed in tool parsing and agent scaffolding
The parser is the sharpest divergence. Qwen2.5 tool use runs through the hermes parser in vLLM because the tokenizer-config template already embeds Hermes-style formatting. Qwen3-Coder-Next requires --enable-auto-tool-choice --tool-call-parser qwen3_coder per the vLLM Qwen3.5/Qwen3.6 usage guide. These are not interchangeable.
On the agent scaffolding side, Qwen-Agent now defaults to the nous template for Qwen3, which affects how the framework constructs the messages list before serialization. Third-party frameworks that hard-code the Hermes tool-call format for Qwen models will produce malformed transcripts when running against Qwen3-Coder-Next.
Pro Tip: When serving Qwen3-Coder-Next through vLLM, do not rely on automatic parser inference. Explicitly pass
--tool-call-parser qwen3_coderand verify with a round-trip smoke test before production deployment. The same principle applies to SGLang: check the framework's Qwen3 parser documentation before assuming Qwen2.5 configuration carries over.
Failure modes to test before fine-tuning or deployment
| Check | What to verify | Tool / Method | Pass condition |
|---|---|---|---|
| Template identity | Training-time template == inference-time template | Byte-compare tokenizer_config.json across environments |
Identical Jinja template body |
| Special-token IDs | <tool_call>, </tool_call>, <|im_start|>, <|im_end|> IDs match |
tokenizer.convert_tokens_to_ids([...]) |
Same IDs in train and serve tokenizer |
| Role boundary ordering | Every <tool_call> assistant turn followed by role: tool turn |
Dataset validation script | Zero violations in full dataset |
| Parallel call IDs | Each tool-response maps to a call ID present in the transcript | ID cross-reference check | 100% ID coverage |
| vLLM round-trip | Single tool call emitted, parsed, result returned, final answer generated | Smoke test with known tool schema | Parser extracts ≥1 ToolCall object |
| SGLang round-trip | Same test under SGLang with Qwen3-compatible parser settings | Smoke test | Parser extracts ≥1 ToolCall object |
| Metric | Threshold | Measurement | Reference |
|---|---|---|---|
| Template byte parity | 100% identical | chat_template diff |
Training vs. serving tokenizer_config.json |
| Special-token ID match | 4/4 tokens identical | convert_tokens_to_ids |
<tool_call>, </tool_call>, <|im_start|>, <|im_end|> |
| Dataset structure validity | 0 malformed tool turns per 10,000 examples | Validation script | Assistant/tool order and call-ID checks |
| Round-trip tool extraction | ≥1 parsed ToolCall in a smoke test |
vLLM or SGLang server call | Deterministic tool schema |
| Inference parser correctness | 100% extraction on 20 repeated prompts | Repeated smoke test | qwen3_coder / matching parser config |
Template mismatch checks
The most common mismatch source is loading the tokenizer from a Qwen2.5 checkpoint while running inference against a Qwen3-Coder-Next model, or the reverse. The template body in tokenizer_config.json is bound to the tokenizer, not the weights; if you swap the tokenizer independently of the model, the serialization will no longer match what the model was trained on.
Concretely: inspect the chat_template key in tokenizer_config.json from your training environment and your serving environment side by side. A diff of even a single character — a whitespace difference in the Jinja template, a changed delimiter string — can shift where role boundaries land in the token stream.
Watch Out: Training-time and inference-time template drift is the hardest class of bug to diagnose because the model generates fluent output throughout. The only observable symptom is that the tool parser returns empty results or extracts malformed JSON. Always check
tokenizer_config.jsonfirst when tool calling fails after a model or environment update.
Round-trip tool-use sanity checks
A round-trip test sends a request that forces a tool call, executes the tool with a known return value, and verifies that the final response incorporates that value. For Qwen3-Coder-Next under vLLM, this requires --enable-auto-tool-choice --tool-call-parser qwen3_coder on the server, a tool schema registered at request time, and a deterministic tool implementation that returns a fixed string.
| Stack | Parser flag | Expected extraction | Common failure |
|---|---|---|---|
| Transformers (direct) | N/A (Jinja template handles it) | ToolCall from apply_chat_template |
Wrong tokenizer loaded |
| vLLM / Qwen2.5 | --tool-call-parser hermes |
ToolCall object in response |
Missing --enable-auto-tool-choice |
| vLLM / Qwen3-Coder-Next | --tool-call-parser qwen3_coder |
ToolCall object in response |
Wrong parser (hermes used instead) |
| SGLang / Qwen3 | Qwen3-specific parser config | ToolCall object in response |
Parser config not updated from Qwen2.5 |
If the call is parseable under Transformers but not under vLLM, the parser flag is the first suspect. If the call is missing in both, the template body or special-token IDs are the cause.
Practical implications for dataset builders and ML engineers
Dataset builders working with TRL or the Hugging Face Trainer face a concrete design decision: whether to reuse the stock Qwen3-Coder-Next template as-is, adapt it for a domain-specific tool schema, or rebuild it for a fundamentally different agent structure. The Qwen-Agent README's explicit nous default for Qwen3 narrows the decision space — the stock template already supports parallel function calls and is the format the vLLM qwen3_coder parser expects. Deviation requires lockstep updates to both training data and serving parser.
Decision matrix:
- Reuse the stock template when your tool schema uses standard JSON-serializable types, your tools fit within the call/result turn structure, and your serving stack is vLLM or SGLang with Qwen3-compatible parser support.
- Adapt the template when your domain tools require a non-standard argument schema, you need additional metadata fields in call or response blocks, or you are integrating MCP tool definitions that diverge from the default format — and when you can update the parser configuration in lockstep.
- Rebuild the template only when you are training a fundamentally different agent architecture (e.g., a step-by-step scratchpad model that uses tool calls as intermediate reasoning steps rather than external executions) and you control the entire inference stack end to end.
When to reuse the stock template
The stock Qwen3-Coder-Next template is the safest baseline for any task where the tool schema maps cleanly to JSON function calls with named parameters. The Qwen-Agent framework's nous default natively handles parallel calls, which covers most agentic code-writing and search scenarios without modification. The vLLM qwen3_coder parser is already calibrated to this format, meaning zero additional serving configuration is required beyond the documented flags.
Pro Tip: Keep your SFT training transcripts as close to the inference-time template as possible. The closer the dataset format is to what the serving parser expects, the lower the probability of silent mismatch after deployment. Any divergence you introduce during dataset construction must be mirrored in the parser — there is no automatic reconciliation at inference time.
When to adapt the template for a domain tool schema
Adaptation is warranted when domain tools carry non-standard metadata — for example, when a code-execution tool must return structured error objects with stack traces, or when tool calls must embed authentication context that the stock nous format does not carry. The DLLM-Searcher paper shows that agentic SFT can enforce strict adherence to custom tool_call formats, but only when the training transcripts contain the custom format consistently.
The risk of adaptation scales with schema complexity. Simple additions (an extra field in the tool result JSON) are low risk if the parser is updated to expect them. Structural changes (replacing <tool_call> delimiters with custom tags) require rebuilding the parser from scratch and are high risk under vLLM and SGLang, which have family-specific parsers that do not expose generic delimiter configuration.
Decision criteria:
- Complexity of schema divergence from stock format: low divergence → adapt; high divergence → rebuild with full parser control
- Parser recoverability: can the target serving stack parse the adapted format with a config change, or does it require code modification?
- Tokenizer stability: does the custom schema require new special tokens? If so, the tokenizer vocab must be extended and the model must be pre-trained or continually trained on the new tokens before SFT.
PAA answers for Qwen tool templates and agentic SFT
Bottom Line: For safe tool transcripts in Qwen3-Coder-Next, enforce five invariants: (1) every tool call appears inside an assistant turn in a
<tool_call>block with valid JSON, (2) every tool result appears as a dedicatedrole: toolturn with a matching call ID, (3) the Jinja template intokenizer_config.jsonis byte-identical between training and inference environments, (4) vLLM is invoked with--enable-auto-tool-choice --tool-call-parser qwen3_coder, and (5) no tool-related content appears inuserturns or merged into surrounding assistant prose.
What is a chat template in LLMs?
A chat template is a Jinja program embedded in a model's tokenizer_config.json that converts a structured Python message list into the flat token sequence the model was trained to process. It is not a text-formatting convention — it is part of the tokenizer's operational contract, and it determines where role boundaries, special tokens, and structured call blocks are placed in the token stream. For Qwen models, the Qwen2.5 model card shows tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) as the canonical invocation; the vLLM docs confirm that this same template mechanism carries tool-use semantics for Qwen2.5, with the Hermes-style format baked directly into tokenizer_config.json.
Pro Tip: The chat template is tokenizer-specific and model-family-specific. Loading the Qwen2.5 tokenizer to process Qwen3-Coder-Next data will apply the wrong Jinja template body, producing a token sequence the Qwen3 model was not trained on. Always load the tokenizer from the same model checkpoint you intend to serve.
How do you format tool responses in a chat template?
Tool responses in Qwen-style transcripts must appear as a dedicated role: tool message in the messages list, not appended to the preceding assistant message. The content of a tool response includes the tool name, the call ID that matches the <tool_call> block that triggered the execution, and the result payload. When apply_chat_template processes this message, it emits a <|im_start|>tool\n...<|im_end|> block at the correct position in the token stream.
For parallel calls, each tool response is a separate role: tool message with its own call ID. The template processes them sequentially in list order. The model then receives a prompt that contains the assistant call block, followed by all tool-response blocks, followed by the open assistant anchor for the final answer.
Watch Out: Malformed tool-response blocks are the most common cause of silent SFT failure in multi-tool transcripts. Specifically: if you omit the call ID field from a tool-response message, the model cannot learn to match results to calls; if you emit the tool response before the assistant call block that triggered it, the supervision signal is causally inverted; and if you insert the tool response into a
userturn, the model treats it as human input rather than execution state.
Why is my Qwen tool call not working in vLLM?
The most frequent cause is parser mismatch. The model emits a correctly formatted tool-call block, but vLLM is either not configured to extract tool calls at all (missing --enable-auto-tool-choice) or is using the wrong parser for the model family. Per the vLLM docs, Qwen2.5 uses --tool-call-parser hermes; Qwen3.5/Qwen3.6 requires --tool-call-parser qwen3_coder. Using the hermes parser on a Qwen3-Coder-Next model means the parser scans for Hermes-format delimiters in output that uses nous-format delimiters — the call exists in the raw generation string but is never extracted.
The second most frequent cause is special-token mismatch introduced during fine-tuning: the model was fine-tuned on a custom tokenizer with modified token IDs for <tool_call> or <|im_end|>, and those IDs no longer match what the vLLM runtime expects.
Pro Tip: To align vLLM parser settings with the Qwen3-Coder-Next template, run the serve command with both
--enable-auto-tool-choiceand--tool-call-parser qwen3_coder. Then execute a round-trip smoke test with a single deterministic tool before routing production traffic. Do not rely on the absence of errors — vLLM will not raise an exception if the parser finds no calls; it will silently return a natural-language response.
Sources and reference implementations
| Source | Type | Contribution |
|---|---|---|
| Qwen2.5-1.5B-Instruct model card | Official HF model card | Canonical apply_chat_template usage, ChatML role structure, baseline generation path |
| vLLM Tool Calling docs | Official framework docs | Hermes parser for Qwen2.5, tokenizer-config template as source of tool-use semantics |
| vLLM Qwen3.5/Qwen3.6 usage guide | Official framework recipe | qwen3_coder parser requirement, --enable-auto-tool-choice flag |
| Qwen-Agent README | Official GitHub repo | nous template default for Qwen3, parallel function call support, agent loop structure |
| Qwen-Agent Qwen3 example | Official GitHub example | Function calling, MCP, code interpreter integration, tool-result return path |
| Awakening the Sleeping Agent (arXiv 2604.08388) | arXiv research paper | Near-zero BFCL accuracy before agentic SFT, Goedel-Prover-V2-32B-SFT benchmark data |
| DLLM-Searcher (arXiv 2602.07035) | arXiv research paper | Agentic SFT rectifying tool_call format adherence, boundary token pre-filling technique |
Keywords: Qwen3-Coder-Next, Qwen2.5-1.5B-Instruct, Qwen2.5-VL-32B-Instruct, ChatML, transformers, TRL, Hugging Face tokenizer, vLLM, SGLang, Qwen-Agent, function calling, tool parser, special tokens, agentic SFT, Jinja chat template